
模型市场
为广大工业用户开展数据模型的开发和业务的数字化转型提供参考。
为广大工业用户开展数据模型的开发和业务的数字化转型提供参考。

 异常检测
异常检测异常检测(Anomaly Detection)是一种用于识别不符合预期行为的异常模式的技术,也叫异常分析(Outlier Analysis 或者 Outlier Detection)或者离群值检测,在工业上有非常广泛的应用场景:
金融业:从海量数据中找到“欺诈案例”,如信用卡反诈骗,识别虚假信贷
网络安全:从流量数据中找到“侵入者”,识别新的网络入侵模式
在线零售:从交易数据中发现“恶意买家”,比如恶意刷评等
生物基因:从生物数据中检测“病变”或“突变”
异常检测方法在多个领域具有强烈的需求,利用异常检测技术可以被用于机器学习任务中的预处理(Preprocessing),防止因为少量异常点存在而导致的训练或预测失败,也可以应用于优化生产过程及质量控制、故障检测等。
针对工业上的异常检测,通过仿真生成的二维数据,建立四种异常检测模型如单类支持向量机、孤立森林、局部异常点检测和椭圆模型拟合,进行了应用并对结果进行了对比。使用几种不同的算法来开发异常检测模型,以预测数据的异常情况。由于提供的数据集没有被标记,所以依赖于统计方法来计算标签,以帮助评估所使用的算法与使用的准确性和敏感性度量。
以 make_blobs 生成的具有异常标签的二维数据,基于上述解决方案,分别使用以上四种异常检测的方法进行异常判断,得到模型训练结果。应用训练好的模型,对新数据进行异常判断,结果如下图所示,其中图中蓝色点表示正常数据,绿色点表示异常数据。
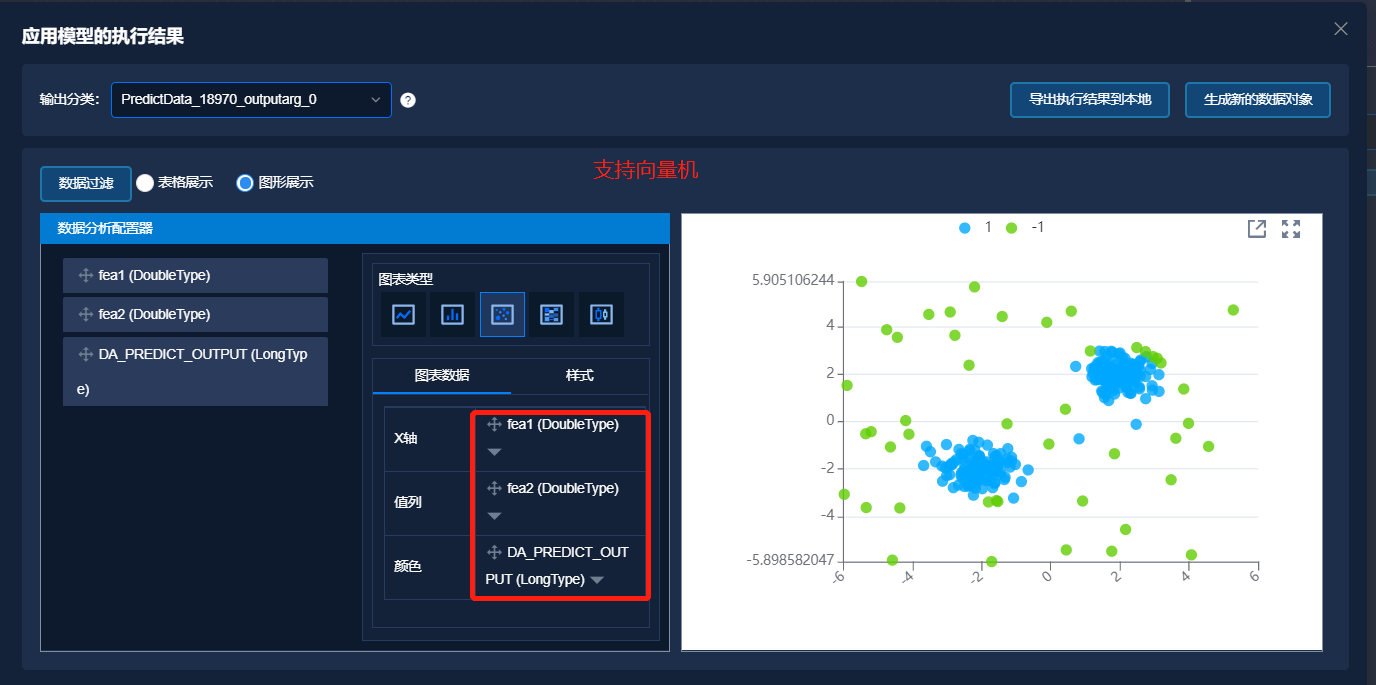
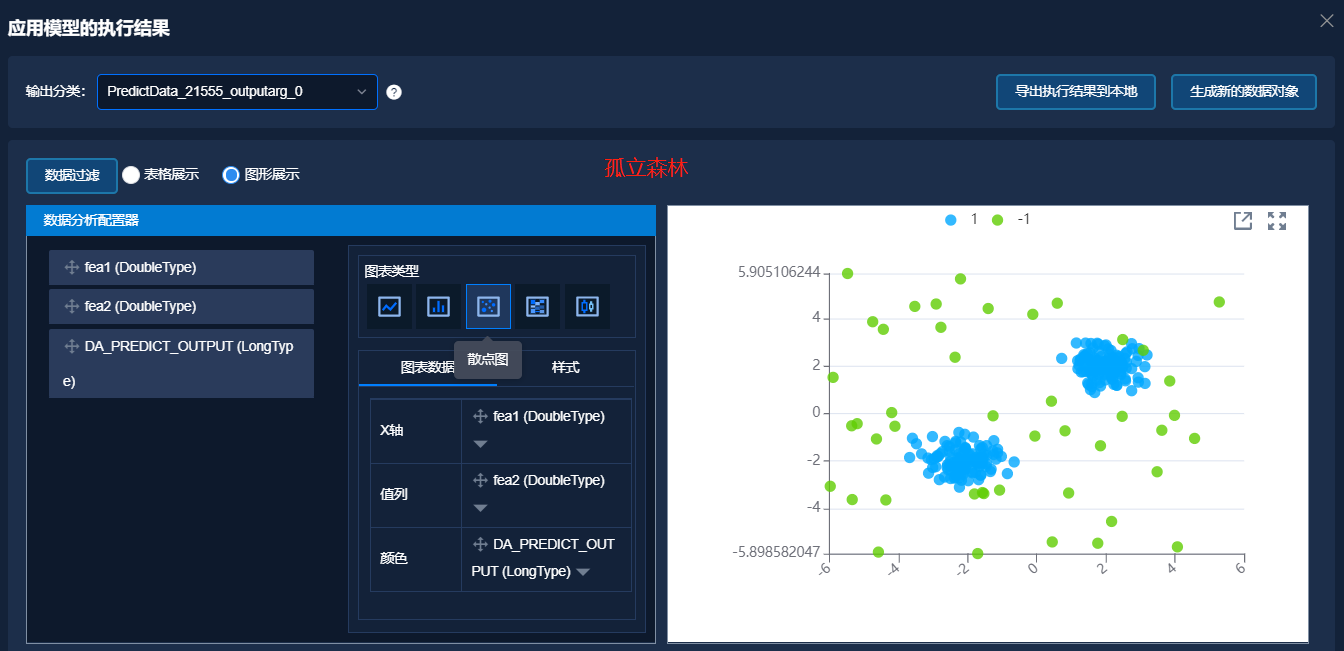
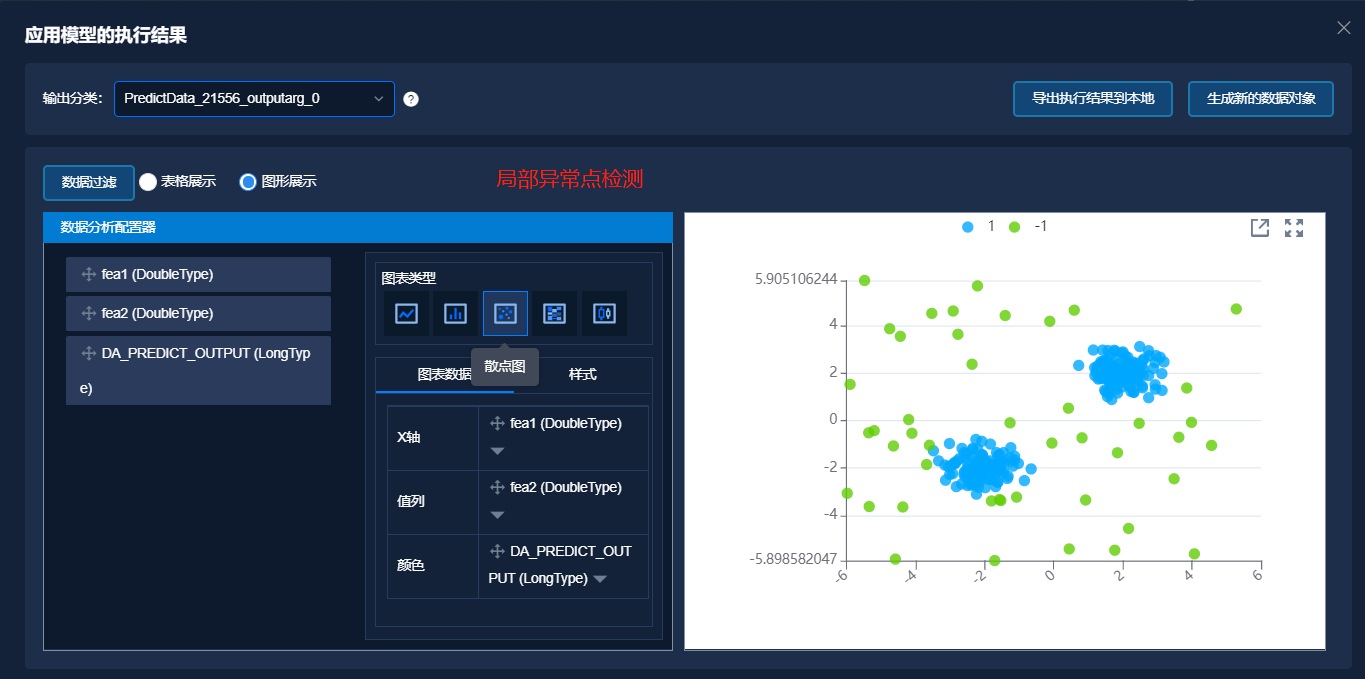
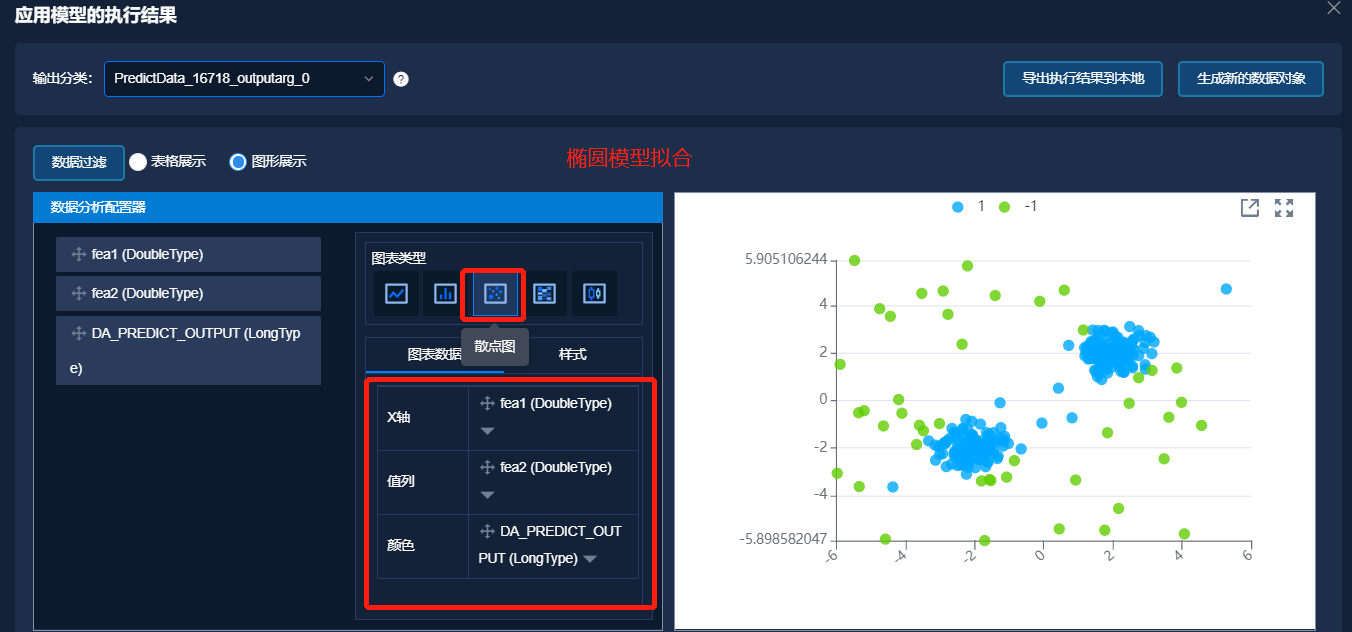
对最后检测到的异常结果数做统计,结果如下表所示。原始数据中异常点个数为 45 个,正常点个数为 255 个。从统计结果看到,四个异常检测算法的性能差异不大。但是面对不同的问题,选择不同的模型效果将更好。
| 算法 | 支持向量机 | 独立森林 | 局部异常点监测 | 椭圆模型拟合 | | :------: | :------------: | :----------: | :----------------: | :--------------: | | 异常点 | 46 | 45 | 45 | 45 | | 正常点 | 254 | 255 | 255 | 255 |
在工业领域,相对来说容易得到正常场景下的训练数据,但故障数据可能相当昂贵,或者根本难以获取。如果训练集样本都是正常样本,选择采用 One-Class SVM;如果训练集样本分布为高斯分布,可选择 Robust covariance;如果训练集样本中既有正常样本又包含异常样本,可选择孤立森林或者 LOF。



